Random Forests: Explained and implemented
Introduction
Random Forests are an ensemble learning method that can be used for performing both regression and classification tasks. Random forests usually outperform decision trees, but their accuracy is lower than gradient boosted trees. It is also useful for dimensionality reduction methods, handling missing values, and outliers.

Decision trees are invariant under scaling and other transformations of feature values, hence robust to the inclusion of irrelevant features and can produce inspectable models.
To be precise, trees with great depth tend to learn a highly irregular pattern. The model starts overfitting their training data: having low bias and high variance, as shown below:

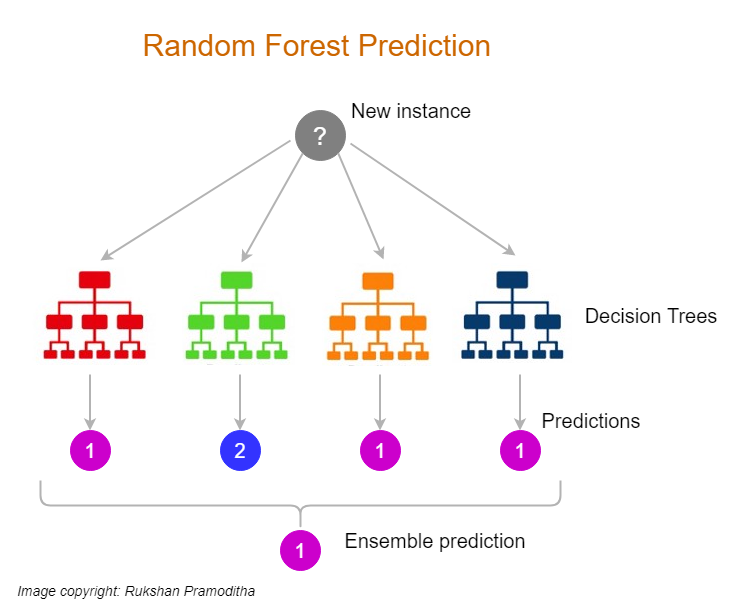
Random forests do an average of multiple deep decision trees which are trained on different parts of the same training set to reduce variance. This also causes a small increase in the bias sometimes, but overall enhances the final performance of the model.
Working of Random Forest
In Random Forest, each tree is planted & grown as follows:
- Say, for the ‘N’ number of cases in the training set, the cases are taken randomly to grow the tree.
- For ‘M’ input variables, number m<<M is specified such that at each node, m variables are selected at random out of the M. The best split on these ‘m’ is used for the distribution. The value of m is held constant while the forest grows.
- Each tree is grown to the largest extent possible
- New data is predicted by aggregating the predictions of the n-tree trees
The forest error rate depends on two things:
- The correlation between any two trees in the forest. Increasing the correlation increases the forest error rate.
- The strength of each individual tree in the forest. A tree with a low error rate is a strong classifier. Increasing the strength of the individual trees decreases the forest error rate.
For a more detailed working, refer: THIS BLOG
Features of Random Forests
- It runs efficiently on large datasets and can handle thousands of input variables without variable deletion.
- It gives estimates of important variables for dimensionality reduction in the classification task.
- It generates an internal unbiased estimate of the generalization error as the forest building progresses.
- It has an effective method for estimating missing data and maintains accuracy when a large proportion of the data are missing.
- It has methods for balancing error in class population unbalanced data sets.
- It computes proximities between pairs of cases that can be used in clustering, locating outliers, or (by scaling) give interesting views of the data.
- The capabilities of the above can be extended to unlabeled data, leading to unsupervised clustering, data views, and outlier detection.
- Generated forests can be saved for future use on other data.
Implementation
For a classification model:
Applications
There are plenty of sectors where Random Forests are used, a few of them are mentioned below for example:
- Random forests algorithm is used in banking to find loyalty of customers, i.e to find customers who can take out plenty of loans and pay interest to the bank properly, and fraud customers
- Random forests can be used in stock predictions, i.e to identify a stock’s behavior and the expected loss or profit.
- Random forest algorithm can be used in the field of medicine i.e, to identify the apt combination of components, or identify diseases through medical records data.
Conclusion
Random Forest is an efficient ensemble technique capable of performing both regression and classification tasks with the use of multiple decision trees and a technique called Bootstrap and Aggregation, commonly known as bagging. This feature of Random Forest makes it different from other traditional ML algorithms.
Read about other ML algorithms & interesting stories on my Medium Blogs
You can reach out to me at:
LinkedIn: https://www.linkedin.com/in/manmohan-dogra-4a6655169/
GitHub: https://github.com/immohann
Twitter: https://twitter.com/immohann

{kind=link}