Support Vector Machine: Explained and Implemented

Through this article, you’ll learn about one of the widely used classifications and regression algorithms: Support Vector Machine (SVM). Assuming that the reader is already accustomed to Logistic regression. If not, you can refer to my article on LR.
Introduction to SVM
An SVM model is another powerful yet flexible machine learning algorithm used for both classification and regression problems. It is primarily used for the classification objectives due to its great potential to handle multiple continuous and categorical variables.

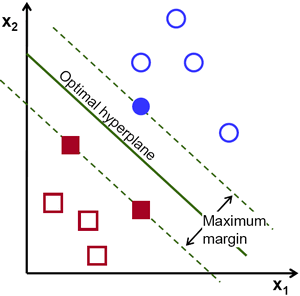
The objective of the support vector machine algorithm is to find a hyperplane in N-dimensional space that distinctly classifies the data points. To separate the data points there can be several hyperplanes chosen. SVM needs to find the planes having the maximum distance between two data points. Maximizing the margin distance reinforces the model such that the classification is performed with higher confidence.

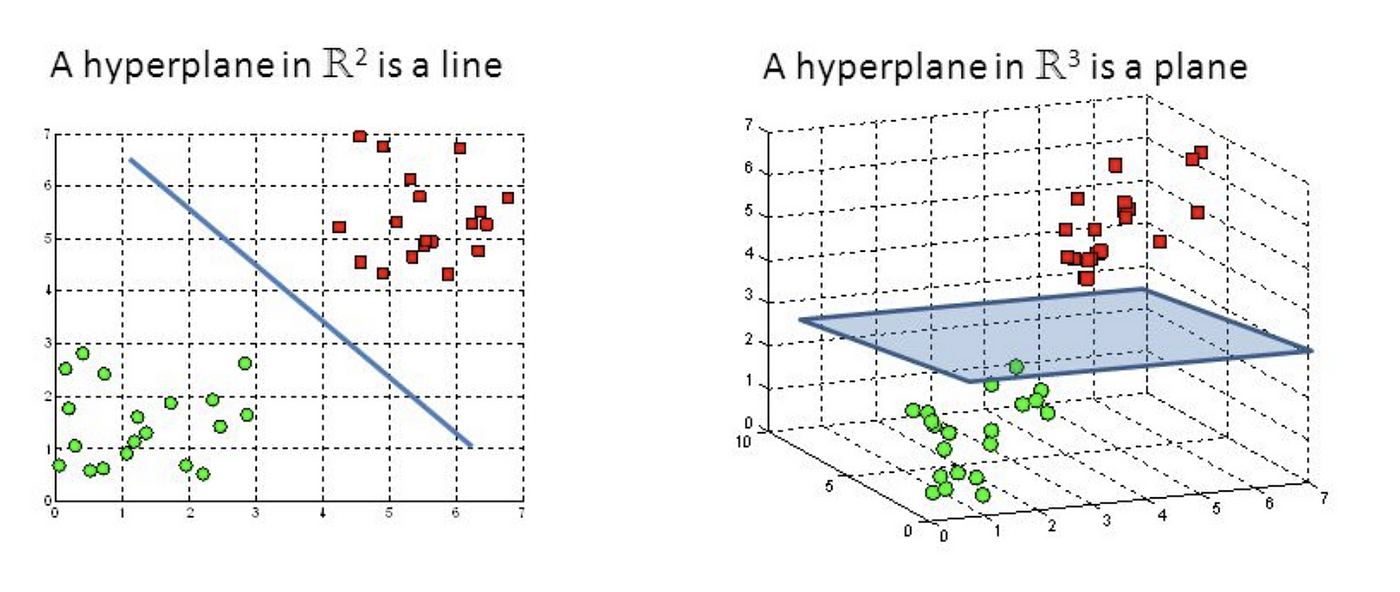
Hyperplanes are decision boundaries that help classify the data points. Data points falling on either side of the hyperplane can be attributed to different classes. Also, the dimension of the hyperplane depends upon the number of features. If the number of input features is 2, then the hyperplane is just a line. If the number of input features is 3, then the hyperplane becomes a two-dimensional plane. It becomes difficult to imagine when the number of features exceeds 3.
Working of SVM
An SVM model is a representation of several classes in a hyperplane in an N-Dimensional space. The hyperplane is generated in an iterative manner by SVM to minimize the error. The goal of SVM is to divide the datasets into classes to find a maximum marginal hyperplane (MMH).

- Support Vectors − Datapoints that are closest to the hyperplane are called support vectors. The separating line will be defined with the help of these data points.
- Hyperplane − As we can see in the above diagram, it is a decision plane or space which is divided between a set of objects having different classes.
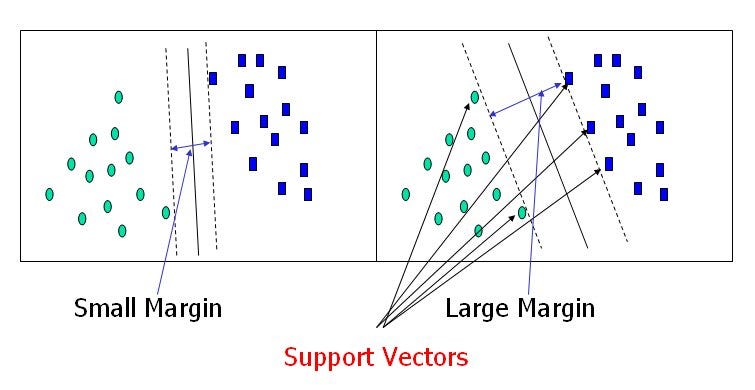
- Margin − It may be defined as the gap between two lines on the closet data points of different classes. It can be calculated as the perpendicular distance from the line to the support vectors. A large margin is considered as a good margin and a small margin is considered as a bad margin.
The main goal of SVM is to divide the datasets into classes to find a maximum marginal hyperplane (MMH) :
- First, SVM will generate hyperplanes iteratively that segregates the classes with maximum distance.
- Then, it will choose the hyperplane that separates the classes correctly.
Implementation
Implementing SVM with custom dataset and visualization.
Implementing SVM with ‘Diabetes’ dataset.
Similar results can be compared with my previous experiment on:
Pros of SVM classifiers
SVM classifiers offers great accuracy and work well with high dimensional space. SVM classifiers basically use a subset of training points hence in result uses very less memory.
Cons of SVM classifiers
They have high training time hence in practice not suitable for large datasets. Another disadvantage is that SVM classifiers do not work well with overlapping classes.
You can reach out to me at:
LinkedIn: https://www.linkedin.com/in/manmohan-dogra-4a6655169/
GitHub: https://github.com/immohann
Twitter: https://twitter.com/immohann

{kind=link}
{kind=link}
{kind=link}